What zero-knowledge machine learning actually is
Zero-Knowledge Machine Learning (ZKML) is a cryptographic protocol that allows a party to prove an AI model executed correctly on specific data without revealing the model’s weights or the input data itself. It merges zero-knowledge proofs (ZKPs) with machine learning algorithms to certify that a computation followed the intended logic, ensuring verifiable integrity while maintaining strict privacy.
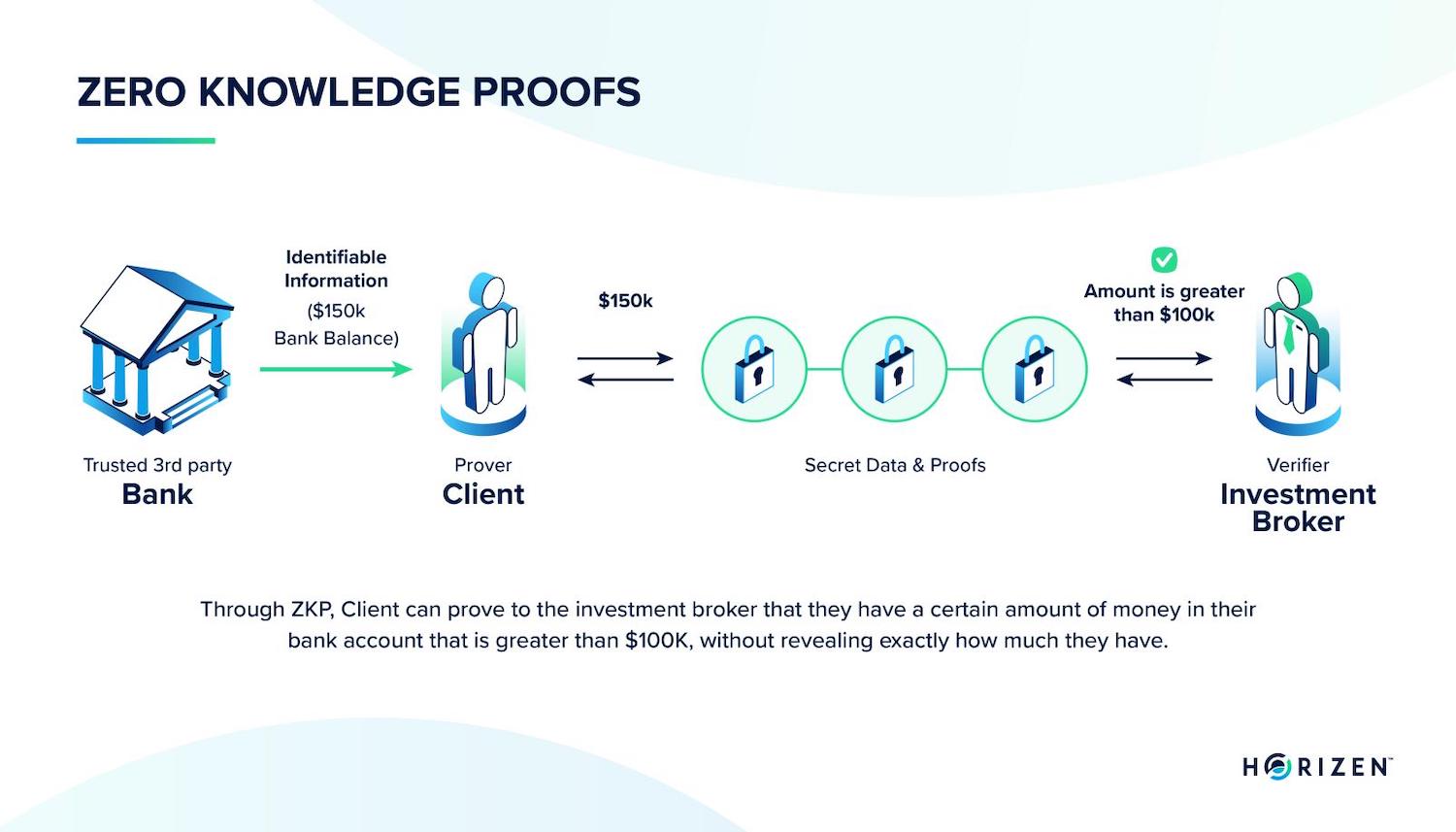
To understand ZKML, it helps to look at how zero-knowledge proofs work in general. Imagine a cave with a single entrance but two pathways that connect at a common door locked by a passphrase. Alice wants to prove to Bob she knows the passcode to the door but without revealing the code to Bob. In ZKML, the "passcode" is the correct execution of the AI model. The prover generates a cryptographic proof that the output was derived from the correct model and data, and the verifier checks this proof without ever seeing the underlying information.
This distinction is critical. Traditional privacy techniques like data encryption protect data at rest or in transit, but they do not prove that the computation performed on that data was correct. ZKML goes a step further by providing a mathematical guarantee that the AI model ran as intended, without exposing the proprietary model architecture or the sensitive input data used to generate the result.
The computational complexity of ZKP protocols can lead to scalability issues, particularly as the number of users increases. For instance, zk-SNARKs require significant computational resources, which can slow down transaction processing and increase costs. However, as hardware and protocol optimizations improve, ZKML is becoming a viable solution for verifying AI in high-stakes environments where trust and privacy are paramount.
Why verifying AI models is harder than verifying code
Verifying machine learning models requires a fundamentally different approach than verifying traditional software. In standard code, execution is deterministic: the same input always produces the same output through a fixed sequence of logical steps. Machine learning models, however, rely on probabilistic inference and continuous mathematical operations that do not map neatly to the discrete binary logic used in most zero-knowledge proof systems.
The primary bottleneck is computational complexity. Neural networks perform billions of floating-point multiplications and additions during inference. Converting these non-deterministic operations into zero-knowledge circuits is exponentially more expensive than verifying simple boolean logic. As noted in recent research, the overhead required to prove a single inference can be thousands of times heavier than the computation itself, creating significant scalability issues for on-chain verification [[src-serp-7]].
This mismatch creates a tension between accuracy and efficiency. To make verification feasible, developers often must approximate floating-point math with fixed-point arithmetic or restrict model architectures to simpler forms. While this makes the proof generation faster, it can introduce small errors that accumulate, potentially compromising the integrity of the result. The goal is to find a balance where the proof is both succinct and mathematically sound without sacrificing the model's predictive power.
| Verification Aspect | Traditional Code | Zero-Knowledge ML |
|---|---|---|
| Logic Type | Deterministic (Boolean) | Probabilistic (Floating-Point) |
| Proof Overhead | Low (Linear/Logarithmic) | High (Exponential/Quadratic) |
| Primary Cost | Execution Time | Proof Generation Time |
| Accuracy | Exact | Approximate (Truncated) |
The challenge is not just about proving that the code ran, but proving that the mathematical operations were performed correctly within a specific error margin. This requires specialized zkML frameworks that can efficiently handle the linear algebra inherent in deep learning, a task that remains an active area of development in cryptographic research [[src-serp-1]].
Proving model integrity without revealing IP
Zero-Knowledge Machine Learning (ZKML) enables organizations to verify that a model is authentic and untampered without exposing the underlying intellectual property. In traditional cloud inference, the provider often has visibility into the model architecture or weights to optimize execution. ZKML eliminates this trust assumption by generating a cryptographic proof that the computation was performed correctly using a specific, authorized model.
Think of this like a sealed envelope. You can prove the envelope contains a valid signature without ever opening it to show the text inside. Similarly, ZKML allows a server to demonstrate that it ran a specific proprietary algorithm on user data, ensuring the output is genuine while keeping the algorithm's source code and training weights completely hidden from the verifier and the infrastructure provider.
This capability is critical for high-stakes industries like finance and healthcare, where model integrity is as important as data privacy. By decoupling verification from visibility, companies can deploy sensitive AI models in untrusted environments without risking trade secret theft. The system guarantees that the inference engine has not been modified by malicious actors or compromised by third-party cloud providers.
However, this security comes with computational overhead. Generating these proofs requires significant processing power, which can impact latency. Organizations must balance the need for absolute integrity against the performance requirements of real-time applications. As the technology matures, optimized circuits and hardware accelerators are reducing this gap, making ZKML a viable option for production-grade AI systems.
Real-world use cases for verifiable AI inference
Use this section to make the Zero-Knowledge Machine Learning decision easier to compare in real life, not just on paper. Start with the reader's actual constraint, then separate must-have requirements from details that are merely nice to have. A practical choice should survive normal use, maintenance, timing, and budget. If a recommendation only works in an ideal situation, call that out plainly and give the reader a fallback path.
The simplest way to use this section is to write down the must-have criteria first, then compare each option against those criteria before weighing nice-to-have features.
The Cost of Verification
Zero-Knowledge Machine Learning promises a future where AI models can be audited without exposing proprietary weights or sensitive user data. However, this privacy comes with a steep computational price tag. The primary bottleneck is not verification, which is typically fast and cheap, but proof generation. Creating a zero-knowledge proof for a complex neural network is an intensely resource-heavy process that currently limits real-time deployment.
Generating proofs for large language models or deep learning architectures requires translating mathematical operations into arithmetic circuits. This translation is lossy and inefficient, often resulting in proof systems that are orders of magnitude slower than standard inference. For instance, proving a single forward pass through a moderately sized transformer model can take minutes or even hours on standard hardware, compared to milliseconds for normal inference. This latency makes ZKML unsuitable for interactive applications like real-time chatbots or live fraud detection without significant architectural compromises.
While ZK-SNARKs are efficient for verification, generating proofs for large neural networks remains computationally expensive, limiting real-time applications.
Hardware acceleration is the only viable path forward to close this gap. Specialized ASICs and FPGAs designed specifically for zk-SNARK or zk-STARK proof generation are beginning to emerge, but they are not yet mainstream. Until these dedicated chips become widely available and cost-effective, the computational overhead will remain a significant hurdle for enterprises looking to adopt ZKML at scale. The industry is currently in a phase where the theoretical benefits outweigh the practical costs, but that balance is shifting as optimization techniques improve.
Frequently asked questions about ZKML
What is a real-world example of zero-knowledge?
To understand how zero-knowledge proofs work without seeing the underlying data, imagine a circular cave with a single entrance that splits into two paths, A and B, connected by a locked door in the middle. Alice wants to prove to Bob that she knows the passcode to open the door, but she does not want to reveal the code itself.
Bob stands outside and asks Alice to come out of either path A or path B. If Alice knows the code, she can open the door if needed to reach the requested exit. If she repeats this process multiple times, the probability that she is guessing correctly becomes negligible. In machine learning, the "cave" is the model, the "code" is the secret weights or training data, and the "exit" is the verified prediction.
What are the disadvantages of using ZKP?
The primary drawback of zero-knowledge proofs is computational complexity. Generating a proof requires significant processing power, which can slow down transaction processing and increase operational costs, particularly as user numbers scale. Protocols like zk-SNARKs are efficient for verification but expensive for the prover to generate.
This overhead creates a trade-off between privacy and speed. For high-frequency financial applications or real-time AI inference, the latency introduced by proof generation can be a bottleneck. Developers must carefully select protocols that balance security requirements with acceptable performance thresholds.
How does ZKML verify AI without leaking secrets?
ZKML combines zero-knowledge proofs with machine learning models to create a cryptographic certificate of correctness. When a model makes a prediction, it generates a proof that the output was derived from the correct weights and input data, without exposing the model architecture or the raw data used.
This allows a verifier to trust the result without needing to inspect the proprietary model or sensitive user information. It ensures that the AI behaved as intended, providing a layer of accountability and integrity for critical decisions in finance, healthcare, and governance.
No comments yet. Be the first to share your thoughts!