Set up the proving environment
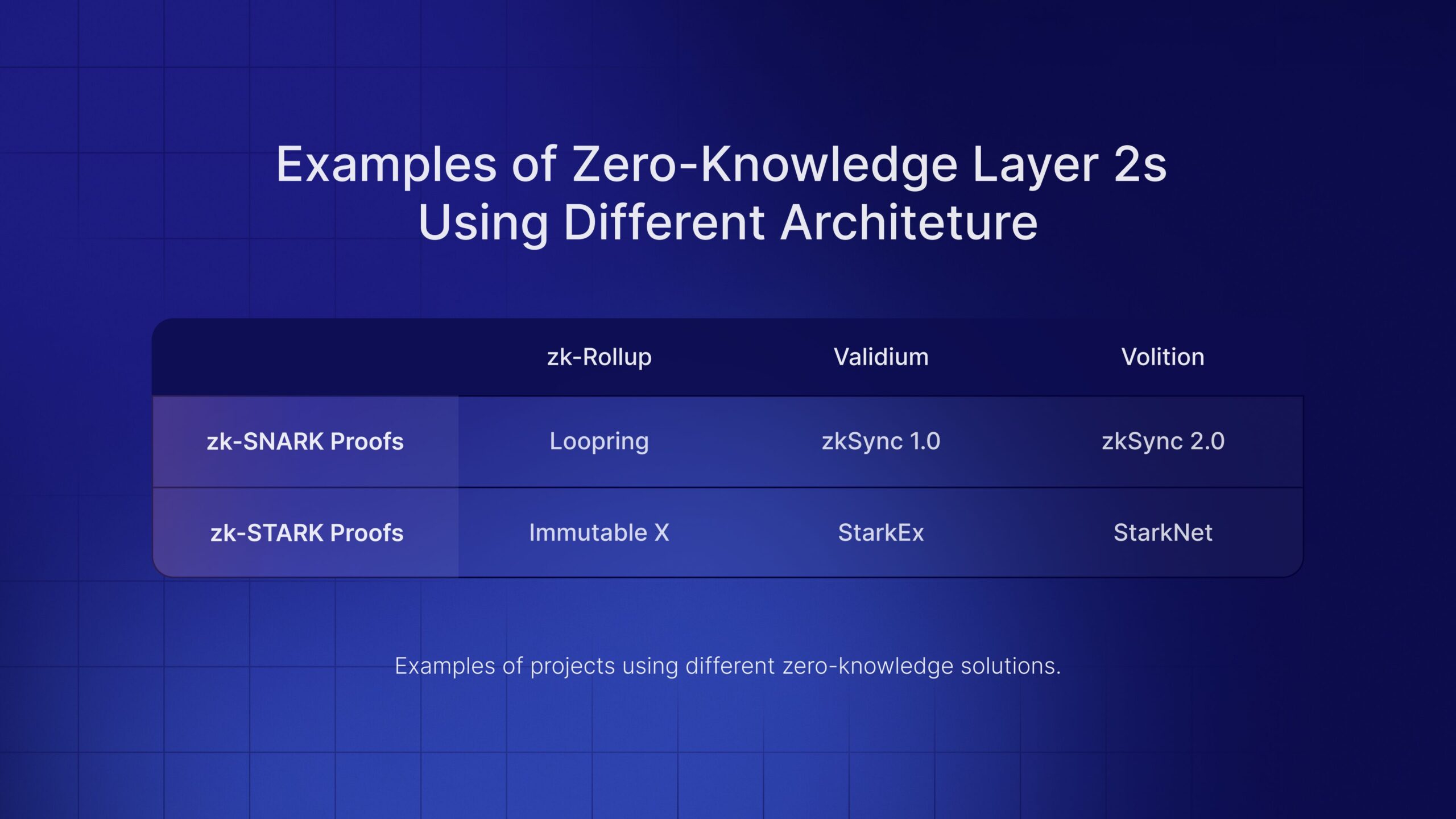
Generating ZK model proofs for L2s requires matching your development framework to the target chain’s verifier contract. The wrong choice creates a mismatch between your off-chain proof and the on-chain verification logic, causing deployment failures that are difficult to debug later. Start by selecting a proving system that supports the specific ML model architecture you intend to compress.
1. Select the ZK framework
Choose a framework based on the model type and your team’s expertise. ZKTorch is designed specifically for compiling machine learning models into zero-knowledge circuits, making it the standard for neural network proofs. For lower-level circuit construction or custom arithmetic gates, Gnark (Go) or Circom (JavaScript) offer more granular control but require deeper knowledge of constraint systems.
2. Verify verifier contract compatibility
Before writing code, inspect the target L2’s on-chain verifier. Each L2 (such as Starknet, zkSync, or Polygon zkEVM) implements a specific verification algorithm (e.g., STARKs vs. SNARKs) and gas-optimized verification contracts. Your selected framework must output proofs in a format that this contract can accept. If the framework outputs Groth16 proofs but the L2 only accepts Plonk, you will need an additional translation layer or a different framework.
3. Configure the proving key
Generate the proving key (PK) and verification key (VK) using your chosen framework. The VK is what gets deployed to the L2 contract. Ensure the parameters for the VK (such as the number of constraints or public inputs) exactly match the model’s complexity. A mismatch here is the most common cause of "proof verification failed" errors on-chain.
4. Test locally with a small batch
Run a local proof generation and verification cycle using a minimal dataset. This confirms that your environment dependencies (compilers, solvers, and runtime libraries) are correctly installed. Verify that the local verifier accepts the proof before attempting any on-chain interaction. This step isolates environment issues from contract logic errors.
Select ZKTorch for ML models or Gnark/Circom for custom circuits. Ensure it supports the specific proof system (SNARK/STARK) required by your target L2.
Review the L2’s on-chain verifier to determine the expected proof format, gas limits, and verification algorithm. Document the required public inputs.
Produce the proving and verification keys locally. Save the verification key parameters to deploy on-chain later.
Run a full proof generation and verification cycle locally with a small batch. Confirm the proof passes the local verifier before attempting on-chain submission.
Compile the model into a circuit
Translating a machine learning model into a zero-knowledge circuit is the most resource-intensive phase of the pipeline. You are converting high-level Python logic into a low-level arithmetic graph that a prover can execute. This process replaces general-purpose virtual machines with a domain-specific instruction set, allowing the prover to skip generic overhead and focus strictly on the mathematical operations required for inference.
The compilation pipeline follows a strict sequence: Model → Graph → Circuit → Proving Key. Each stage narrows the scope of the computation, preparing the data for efficient proof generation.
Begin by exporting your trained model weights and architecture into a portable format like ONNX or TorchScript. This step isolates the inference logic from the training environment, creating a static snapshot of the model that can be inspected and transformed. Ensure the export includes all necessary metadata, such as input shapes and activation functions, to prevent runtime errors during the subsequent graph conversion.
Use a tracing tool to record the sequence of operations performed during a forward pass. This generates a computational graph where nodes represent operations (add, multiply, softmax) and edges represent data flow. The tracer captures the exact control flow, including conditional branches and loops, which must be flattened or unrolled to fit the static nature of arithmetic circuits. This graph is the blueprint for the circuit.
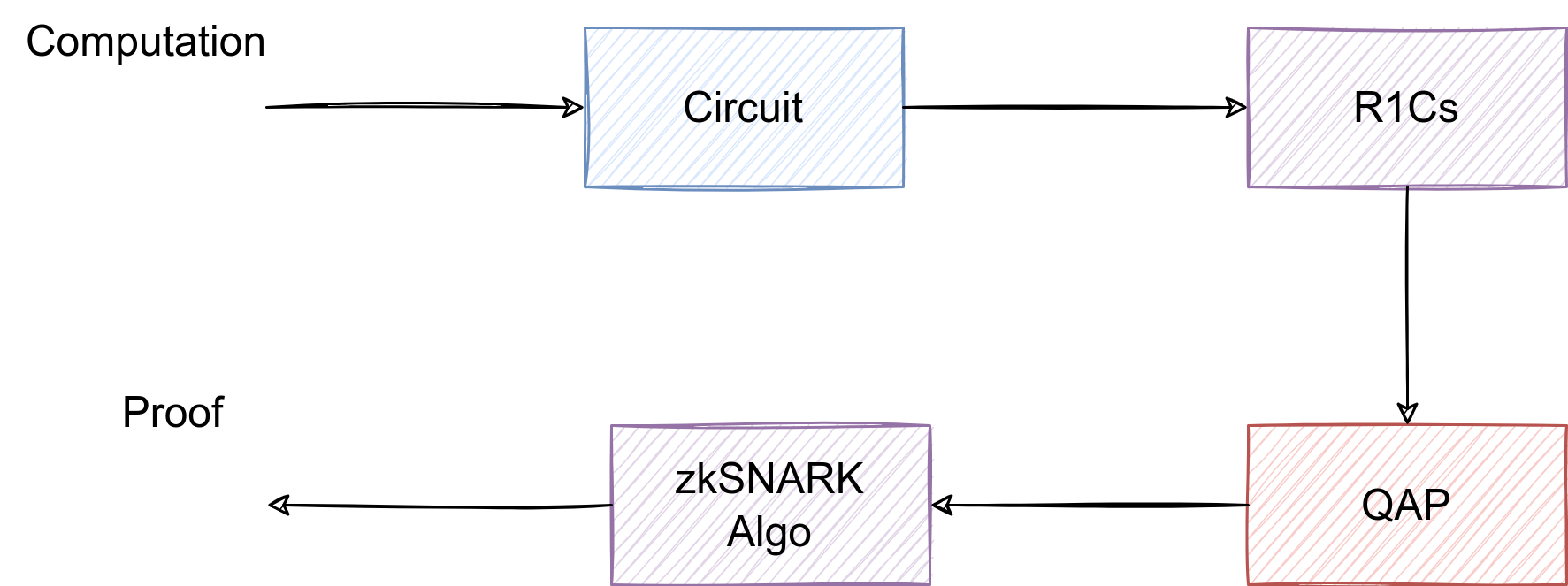
Map each node in the computational graph to constraints in a specific ZK-friendly field, such as BN254 or Pasta. This involves replacing high-level functions with their arithmetic equivalents. For example, a ReLU activation becomes a constraint that enforces $y = \max(0, x)$, and a matrix multiplication becomes a series of dot-product constraints. This stage is where model-specific optimizations shine, as you can choose constraints that are cheaper for the prover to evaluate.
Compile the constraint system into a proving key (PK). This key contains the structured reference string and the internal mapping of variables to constraints. Generating the PK is a one-time cost that depends on the size of the circuit (number of gates). A larger, more complex model results in a larger PK, which increases the time required for proof generation but does not affect verification speed. Store this key securely, as it is required for all subsequent proofs.
The choice of compiler framework significantly impacts the efficiency of this process. Tools like ZKTorch are designed specifically for this translation, offering pre-built components for common ML operations. By leveraging these specialized tools, you avoid the need to manually write low-level constraints for every operation, reducing development time and the risk of errors.
Optimize for proof generation latency
High-throughput L2s cannot afford the computational drag of slow witness generation. Optimizing for latency requires treating the proving pipeline as a critical path, not a background task. The goal is to minimize the time between transaction finality and proof availability, ensuring the L2 can sustain its target TPS without stalling.
1. Parallelize witness generation
The most immediate gain comes from breaking the monolithic witness generation step into parallelizable chunks. Modern ZK frameworks allow you to split the execution trace across multiple CPU cores or nodes. Instead of processing transactions sequentially, distribute the workload. This approach reduces the witness generation time linearly with the number of available cores, provided the underlying circuit supports such decomposition.
2. Use incremental proving
For L2s that process frequent, small updates, incremental proving is often faster than generating a full proof from scratch. Incremental proofs update the state commitment based on previous proofs, leveraging the existing circuit state. This technique significantly reduces the computational overhead for each new block, making it ideal for high-frequency trading or gaming applications where latency is paramount.
3. optimize circuit limits to account for
Reduce the number of constraints in your circuit. Every additional constraint increases the proving time. Work with your circuit designers to minimize the gate count by using more efficient arithmetic operations or by simplifying the logic where possible. A leaner circuit not only proves faster but also generates smaller proofs, reducing verification costs on the L1.
4. Select the right proving framework
Different frameworks offer different trade-offs between proving time and proof size. For latency-sensitive applications, choose a framework that prioritizes fast proving, even if it means slightly larger proof sizes. Some frameworks support hardware acceleration (GPU/FPGA) for specific operations, which can drastically cut down proving times. Evaluate frameworks based on their ability to scale with your specific workload.
5. Implement proof aggregation
Instead of submitting individual proofs for every block, aggregate multiple proofs into a single recursive proof. This reduces the number of L1 transactions and the overall verification burden. While aggregation itself takes time, it is often faster than verifying many individual proofs, especially when the L1 gas costs are high. This technique is essential for maintaining throughput when L1 congestion occurs.
| Technique | Latency Impact | Implementation Complexity |
|---|---|---|
| Parallel Witness Gen | High | Medium |
| Incremental Proving | High | High |
| Circuit Optimization | Medium | High |
| Framework Selection | Medium | Low |
| Proof Aggregation | Medium | Medium |
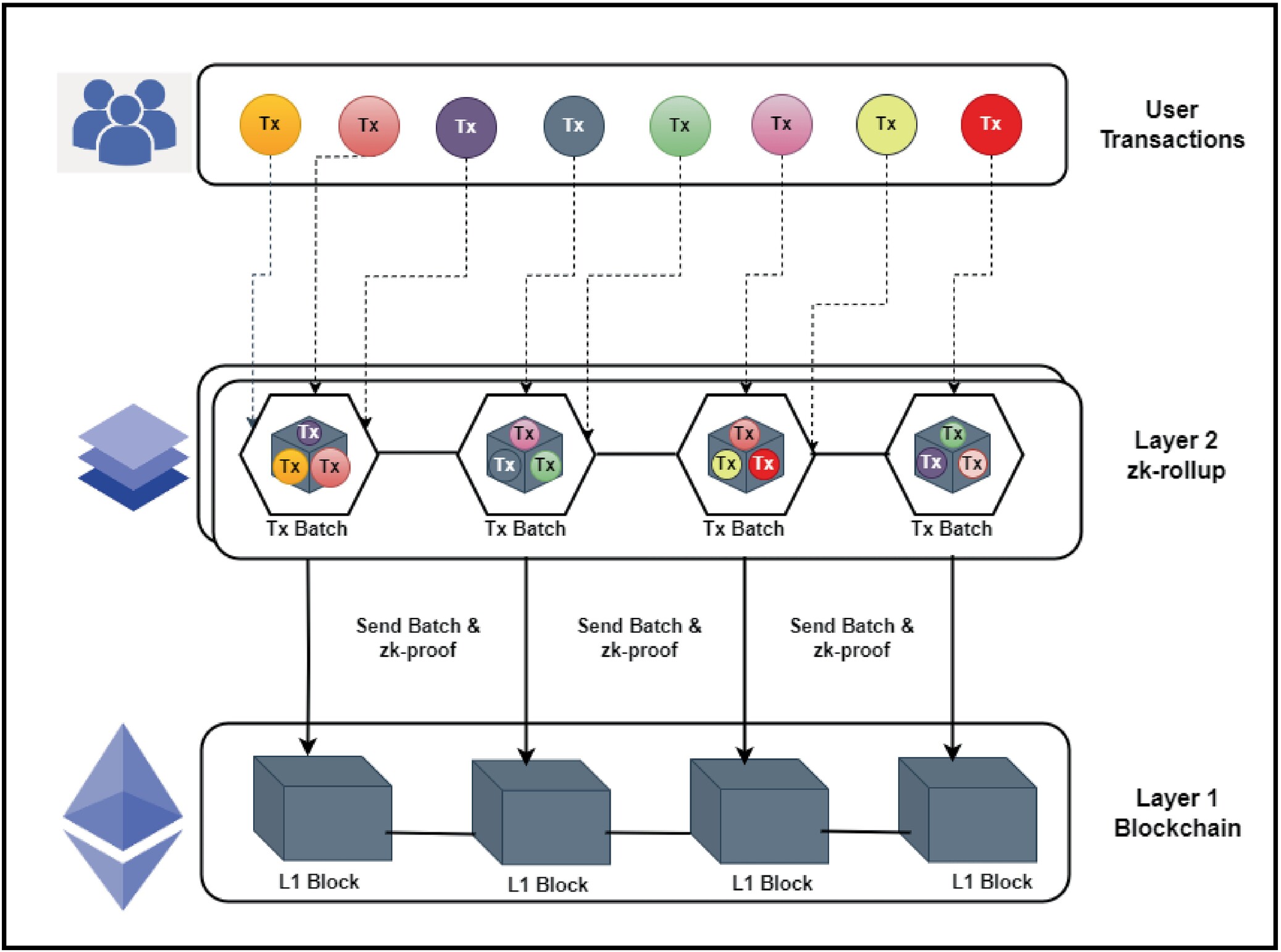
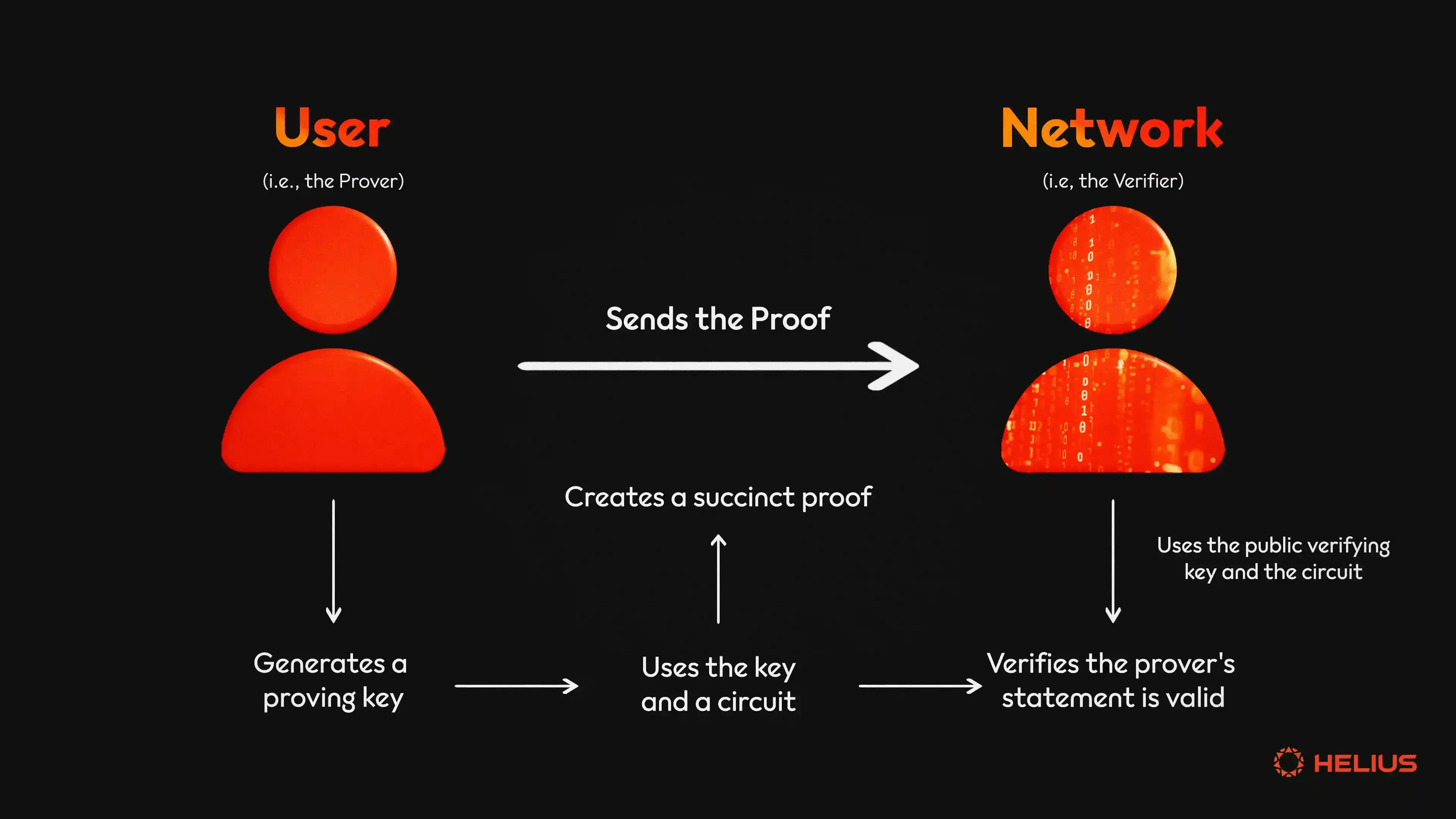
Verify the proof on-chain
Once you have generated the ZK model proof, the final step is submitting it to the L2 verifier contract. This on-chain verification is what transforms a computational result into a trustless, immutable state. Without this step, the proof remains an off-chain artifact with no effect on the blockchain’s state.
1. Prepare the verification call
Construct the transaction payload to call the verifyProof function on your L2’s verifier contract. You must pass the proof data (typically a serialized array of field elements) and any required public inputs. Ensure the data format matches the contract’s expectations exactly; a mismatched byte order or incorrect field size will cause the verification to fail silently or revert.
2. Submit the transaction
Broadcast the transaction to the L2 network. Because ZK verification involves heavy elliptic curve pairing operations, gas costs can be significant depending on the proof system (e.g., Groth16 vs. Plonk). Monitor the transaction status. If the gas limit is too low, the transaction will fail before the verification logic executes. If the gas limit is sufficient, the node will run the verification circuit.
3. Interpret the response
The contract will return a boolean: true if the proof is valid, or false (or a revert) if it is invalid. A successful return updates the L2 state, allowing the next block to build on this verified computation. If verification fails, the state remains unchanged, and you must debug the proof generation phase. This binary outcome ensures that only mathematically valid computations are accepted by the network, maintaining the integrity of the ZK model proofs.
Common Pitfalls in Model Proving
When generating zero-knowledge proofs for L2s, small implementation errors can cause proving failures or, worse, silent correctness issues. The most frequent errors stem from incorrect witness formatting, arithmetic gate overflows, and mismatched curve parameters.
Incorrect Witness Formatting
The witness must strictly adhere to the circuit’s expected input structure. If the witness vector is malformed—such as having the wrong dimension or incorrect data types—the prover will either crash or produce an invalid proof. Always validate the witness against the circuit schema before submission.
Arithmetic Gate Overflows
ZK circuits operate over finite fields. If intermediate calculations exceed the field modulus without proper modular reduction, the result will be incorrect, leading to a proof that verifies as false. Use libraries that enforce modular arithmetic automatically to prevent silent overflows.
Mismatched Curve Parameters
Ensure the elliptic curve used for the proof system matches the one specified in your L2’s verification contract. A mismatch between the proving curve (e.g., BN254) and the verification curve (e.g., BLS12-381) will cause the verifier to reject the proof entirely. Double-check curve constants during integration.
-
Validate witness vector dimensions and types against circuit schema
-
Confirm all arithmetic operations use modular reduction
-
Verify proving curve matches L2 verification contract parameters
-
Run a test proof with a known-correct witness to ensure end-to-end flow
Frequently asked questions about ZK proofs
Does zero-knowledge proof exist?
Yes. Zero-knowledge proofs (ZKPs) were introduced by Goldwasser, Micali, and Rackoff in 1985. They are probabilistic and interactive proofs that efficiently demonstrate membership in a language without conveying any additional knowledge. Today, they are a foundational cryptographic primitive used in everything from blockchain privacy to secure computation.
What is the future of ZK?
Experts say ZK proofs have the potential to revolutionize various industries, from finance and healthcare to decentralized systems like blockchain. Independent research shows that ZK proof generation will become a $10 billion market by 2030. As AI models generate more sensitive data, ZK proofs allow apps to verify results or user credentials without exposing the underlying models or raw data.
Does XRP use ZKP?
The XRP Ledger has integrated with Boundless, bringing native zero-knowledge proof verification to the ledger for the first time. Institutions can now verify transactions without revealing amounts, senders, or receivers, adding a layer of privacy to the public ledger while maintaining regulatory compliance.
Can Cardano add ZK proofs?
Cardano already supports ZKPs through its smart contract capabilities. Key features include decentralized identity (DID), which allows users to prove their identity or credentials without exposing personal information. This enables private transactions and secure identity verification directly on the Cardano network.
No comments yet. Be the first to share your thoughts!