
In the shadowy chessboard of global AI development, where datasets are the hidden pawns dictating model moves, trust has become the ultimate kingmaker. Imagine deploying a large language model in finance or healthcare, only to question if it feasted on pirated data or biased scraps. Enter zero-knowledge proofs (ZKPs) for ZK proofs AI training data verification - a cryptographic sleight-of-hand that proves your model's model provenance ZK without spilling a single byte of sensitive training secrets. This isn't mere hype; it's the privacy-preserving shield enabling auditable AI empires.

At its heart, a ZKP lets a prover convince a verifier of a statement's truth - say, "this model trained on licensed, ethical data" - sans revealing the data itself. Traditional audits demand full exposure, breeding vulnerabilities and compliance nightmares. ZKPs flip the script: commit to datasets via hashes, train the model, then generate succinct proofs attesting to correct execution. Verifiers check the proof in milliseconds, confident in training data verification zero knowledge without prying eyes. This unlocks AI dataset licensing proofs, where creators monetize data origins while regulators nod approval.
The Imperative for Privacy-Preserving AI Provenance
Geopolitical tensions amplify the stakes. Nations hoard data troves, corporations battle IP lawsuits, and open-source models risk tainting with copyrighted sludge. Without verifiable provenance, AI risks regulatory guillotines - think EU AI Act mandates or U. S. executive orders demanding transparency. ZKPs emerge as the diplomat, bridging privacy preserving AI provenance with unassailable trust. They don't just verify; they empower decentralized training, where collaborators prove contributions sans collusion fears.
5 Core ZK Proof Benefits for AI Data
- 1. Data Privacy: ZK proofs, as in ZKPROV, verify LLM training on authorized datasets without revealing sensitive data or parameters, safeguarding confidentiality in healthcare and finance.
- 2. Licensing Compliance: Prove models trained on licensed data via succinct proofs like Verifiable Fine-Tuning, ensuring regulatory adherence without exposure.

- 3. Bias Auditing Without Exposure: Audit for biases in committed datasets using zkPoT from ACM, confirming fair training processes cryptographically without data leaks.

- 4. Scalable Verification: Frameworks like zkFL-Health enable efficient, verifiable collaborative training at scale with ZKML, supporting large models trustlessly.

- 5. Decentralized Model Markets: Unlock trustless markets by proving training provenance, as in ZKPROV and Train-ProVe, fostering open AI ecosystems without data risks.

Consider the ripple effects. Enterprises can license datasets confidently, knowing proofs enforce terms. Researchers audit for biases or toxins in training corpora without NDAs. Even adversarial settings, like multi-party federated learning, gain verifiability. This isn't incremental; it's foundational, reshaping AI from black-box lottery to crystalline ledger.
ZKPROV: Pioneering Dataset Provenance Verification
Leading the charge is ZKPROV, crafted by Mina Namazi, Alexander Nemecek, and Erman Ayday. This framework ingeniously binds LLMs to their training datasets via ZKPs, letting users probe responses assured they're rooted in authorized sources. No parameter leaks, no dataset peeks - just ironclad assurance. Published on arXiv in June 2025, ZKPROV tackles the provenance void head-on. Provers commit datasets publicly, train, then issue proofs linking model outputs to those commitments. Verifiers query the model, validating responses against proofs in real-time.
"ZKPROV bridges the gap by providing dataset provenance verification without the need for data exposure, " the authors assert, underscoring its novelty over prior works demanding full reveals.
Why does this matter strategically? In macro terms, it democratizes high-quality data access. Small teams prove equivalence to proprietary giants; markets emerge for provable datasets. Scalability remains key - ZKPROV leverages efficient SNARKs, proving feasible even for billion-parameter models.
Emerging Frontiers: zkFL-Health and Verifiable Fine-Tuning
ZKPROV sets the stage, but the board widens. zkFL-Health, from Savvy Sharma and team (arXiv, December 2025), fuses federated learning with ZKPs and TEEs for medical AI. Hospitals collaborate on models, proving correct updates sans exposing patient records. Proofs confirm computations match specs, dissolving trust deficits in siloed healthcare data.
Meanwhile, Hasan Akgul's verifiable fine-tuning protocol (arXiv, October 2025) targets LLMs precisely. Start from a public base model, commit to a dataset and training script, fine-tune, and emit a succinct ZKP. Regulators or deployers verify the lineage instantly, ideal for decentralized or high-stakes apps. These aren't silos; they're synergistic, painting a 2026 and landscape where every model ships with embedded trust credentials.
Critically, performance hurdles crumble. Early ZKML proofs ballooned to gigabytes; now, they're kilobytes with sub-second verification. Opinion: skeptics decry overheads, but as hardware accelerates - think recursive SNARKs on GPUs - ZK becomes default infrastructure, much like HTTPS secured the web.
Hardware isn't the only accelerator; software innovations like zkFL-Health's hybrid TEE-ZKP stack slash proof generation times by orders of magnitude, making ZK proofs AI training data viable for resource-constrained edge devices. This convergence signals a tipping point: verifiable AI isn't a luxury, it's the new baseline for models handling real stakes.
Overcoming Hurdles: Scalability and Adoption Barriers
Detractors point to proof generation's computational heft - training a model then proving it can demand days on clusters. Yet, this overlooks recursive proofs and plonkish arithmetization, which compress verifications to tweet-sized artifacts. ZKPROV's authors clock proofs at under 10MB for modest LLMs, with verification in 50ms. My take: early HTTPS faced similar compute gripes, dismissed by visionaries who saw the trust multiplier. Today, ZKML libraries like ezkl and snarkjs democratize access, letting indie devs spin up model provenance ZK attestations overnight.
Adoption lags in regulatory voids, but winds shift. The EU AI Act's high-risk classifications mandate traceability; ZKPs deliver without data dumps. U. S. bills echo this, eyeing blockchain-tied proofs for federal AI. Enterprises, wary of IP bleed, pilot ZKPROV forks for internal audits, proving compliance sans lawyers' feast.
Accelerating ZK AI Adoption
- Open-source proof tooling: Democratize access with frameworks like ZKPROV, enabling developers to verify LLM training on authorized datasets without exposing data, fostering rapid innovation and trust.

- GPU-optimized SNARK circuits: Harness hardware accelerations from ZKML advancements (a16z crypto), slashing proof generation times for scalable AI verification in high-throughput environments.
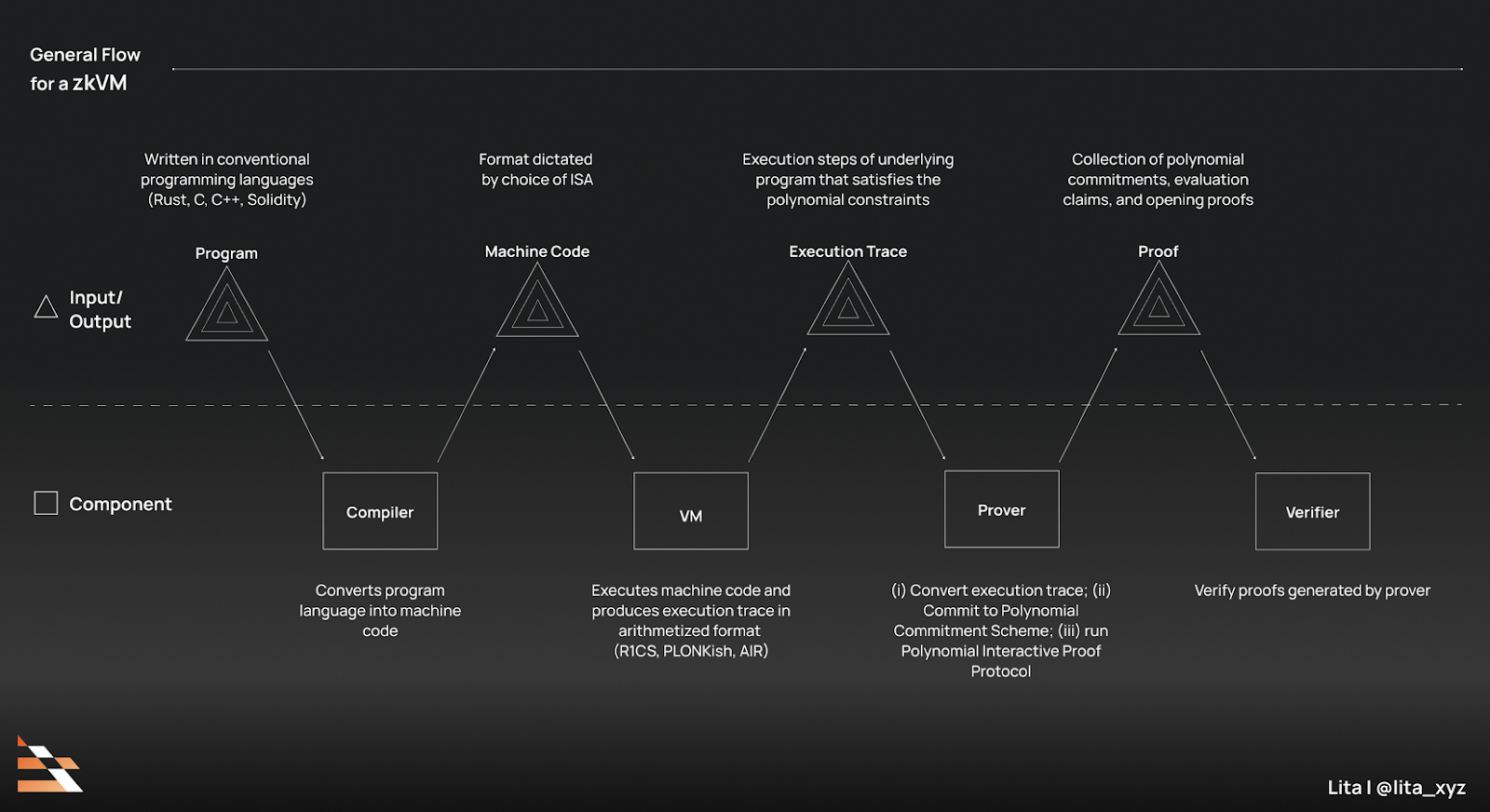
- Hybrid ZK-TEE pipelines: Integrate ZKPs with TEEs as in zkFL-Health, ensuring privacy-preserving federated learning for medical AI with verifiable correctness across institutions.

- Standardized dataset commitments: Adopt auditable commitments from Verifiable Fine-Tuning protocols, proving models trained on committed datasets without revelation, standardizing trust in regulated AI deployments.
- Incentive markets for verified data: Launch decentralized markets rewarding ZK-verified datasets, building on ZKPROV and zkPoT (ACM), to crowdsource high-quality, provenance-proven training data for trustworthy AI ecosystems.

Interoperability looms large. Siloed proofs fragment trust; enter universal verifiers, where a ZKPROV attestation slots into zkFL-Health workflows seamlessly. This composability births ecosystems: data marketplaces trading hash-committed bundles, models auctioned with baked-in proofs, regulators querying chains of custody in seconds.
Sectoral Transformations: Finance, Healthcare, and Beyond
In finance, where I cut my teeth dissecting macro flows, ZKPs fortify quant models against data laundering. Prove your alpha signal trained on licensed feeds, not scraped tweets - regulators exhale, investors pour in. Healthcare amplifies: zkFL-Health lets oncologists federate tumor scans, yielding models that predict outcomes with proven pedigree, patient privacy intact. No more silos starving AI of scale.
Creative domains disrupt too. Text-to-image generators like those in Train-ProVe validations embed provenance, quelling artist lawsuits. Deployers query: "Did Stable Diffusion ingest my portfolio?" Proofs reply unequivocally, fostering licensed creativity loops. Decentralized AI markets flourish - think prediction platforms where models compete on verifiable accuracy, not hype.
Visionaries at a16z crypto nailed it: ZKPs demand trustlessness for every digital artifact. Coupled with Kudelski's ZKML rigor, we edge toward AI where provenance is as routine as SSL certs.
Charting the Horizon: A Verifiable AI Renaissance
By 2030, expect ZK-integrated stacks as standard. Platforms like ZKModelProofs. com pioneer this, offering turnkey tools for training data verification zero knowledge and AI dataset licensing proofs. Developers upload datasets, train, attest - done. Enterprises audit chains, ensuring privacy preserving AI provenance scales globally.
Geopolitically, this levels fields. Data-rich nations can't gatekeep; proofs enable sovereign models trained on licensed global scraps. Bias audits become routine, sans exposure risks. My chessboard lens sees checkmate for opaque AI: transparent, private, unstoppable.




No comments yet. Be the first to share your thoughts!