
In the rapidly evolving landscape of machine learning, where models like XGBoost power everything from fraud detection to medical diagnostics, a nagging question persists: can we truly trust the training process? Data provenance isn't just a technical footnote; it's the bedrock of reliability in AI systems. ZKBoost emerges as a game-changer, offering zero-knowledge proofs for verifiable XGBoost training data provenance. This protocol allows model owners to cryptographically attest that their XGBoost models were trained correctly on committed datasets, all without exposing sensitive data or hyperparameters. Drawing from the arXiv paper by Nikolas Melissaris and team, ZKBoost bridges the gap between high-performance gradient boosting and privacy-preserving verification, fostering a more trustworthy AI ecosystem.
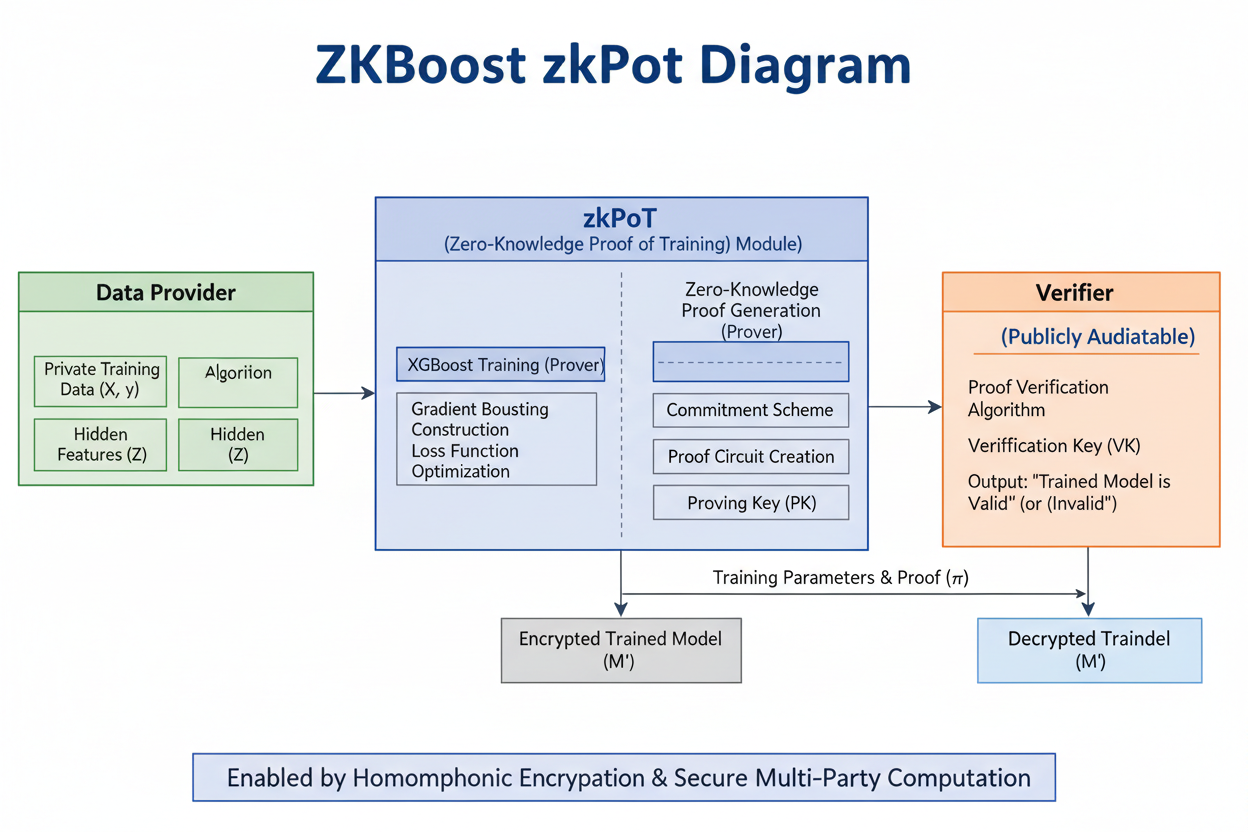
XGBoost has long reigned as a staple in machine learning arsenals due to its speed, scalability, and predictive prowess. Yet, its widespread adoption amplifies risks around AI dataset compliance ZK demands. Enterprises face mounting pressure from regulations like GDPR and emerging AI acts to prove data origins and training integrity. Traditional audits fall short; they demand full disclosure, stifling collaboration and innovation. ZKBoost flips this script with its zkPoT framework, enabling zero knowledge verifiable training that scales to real-world datasets while maintaining near-native accuracy.
Navigating Nonlinear Hurdles in Gradient Boosting
At the heart of XGBoost lies a series of nonlinear operations - think tree splits, histogram approximations, and exponential loss functions - that defy easy arithmetic circuit representation. Proving these in zero-knowledge has been a cryptographic nightmare. ZKBoost's ingenuity shines here: it introduces a fixed-point arithmetic implementation of XGBoost, tailored for zk-SNARK compatibility. This isn't a crude approximation; tests show it holds accuracy within 1% of standard XGBoost on benchmarks like Higgs and Covertype.
The shift to fixed-point computations unlocks VOLE-based proofs for those pesky nonlinear gates, slashing proof times dramatically.
VOLE, or vector oblivious linear evaluation, proves pivotal. It handles the multiplication-heavy nonlinearities with efficiency rivaling specialized ML circuits like zkVC or zkGPT. From a long-term view, this modularity positions ZKBoost as a foundational layer, much like a wide economic moat protects enduring businesses. Developers aren't locked into one prover; the generic zkPoT template adapts across frameworks.

Building the Proof Supply Chain with Consortium Momentum
The ZKBoost Consortium Governing Council marks a pivotal evolution. With 42 members spanning Layer 1 blockchains, Layer 2 partners, and prover networks, it's architecting standards for proof abstraction. Imagine outsourced proving as seamless as cloud compute: model trainers generate commitments, verifiers check proofs, all in a decentralized trust-minimized flow. This collaborative push addresses scalability bottlenecks, funding optimizations that could halve proving costs over time.
ZKBoost Workflow: Verifiable Training in 4 Thoughtful Steps
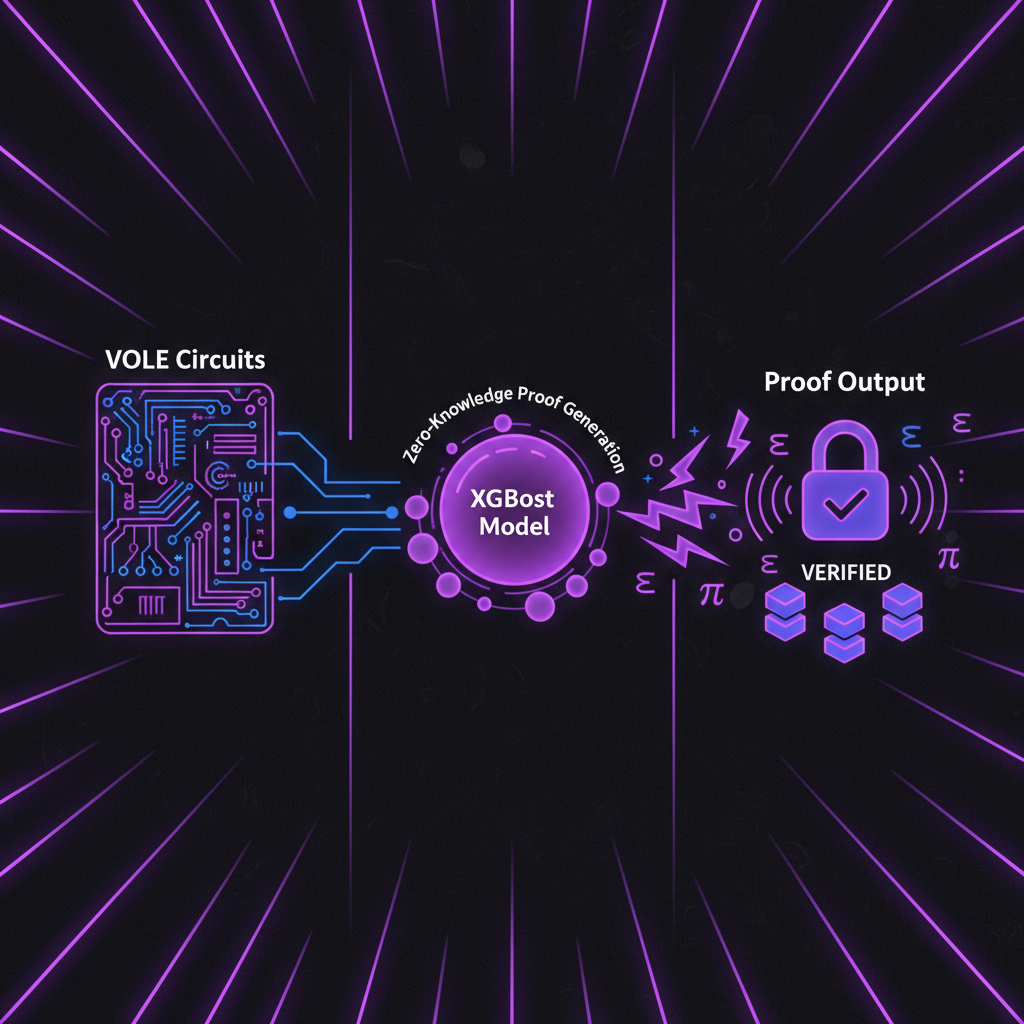

Consider the implications for verifiable ML model training. In regulated sectors, ZKBoost proofs serve as audit trails, preempting disputes over data licensing or bias claims. Researchers gain a tool to share models credibly, accelerating open science without IP leaks. Even in DeFi, where XGBoost drives risk models, zkPoTs ensure tamper-proof training, aligning incentives across the stack.
From Theory to Practical Deployment
Proof-of-concept runs on real datasets underscore viability. Proving a full XGBoost training circuit clocks in at minutes on modest hardware, a far cry from hours in prior zkML attempts. The fixed-point design sidesteps floating-point woes, while histogram optimizations prune circuit bloat. Nikolas Melissaris et al. emphasize VOLE's role in nonlinear fidelity, pushing boundaries where recursion-based systems falter.
Yet, ZKBoost isn't flawless. Circuit depth demands careful hyperparameter tuning, and dataset size caps practical proofs today. Still, as hardware accelerators like zkSpeed mature, these friction points fade. My perspective, shaped by decades tracking sustainable tech trajectories, sees ZKBoost as an investable bet: it compounds value through network effects in the ZK proofs training data provenance space.
Looking ahead, the ZKBoost Consortium's momentum hints at exponential scaling. With 42 organizations - from Layer 1 blockchains to prover networks - rallying around proof supply chain standards, we're witnessing the birth of a verifiable ML infrastructure moat. This isn't hype; it's deliberate architecture for outsourced proving, where trainers commit data, generate zkPoTs, and verifiers audit without friction. Over time, such coordination mirrors the compounding advantages of network-aligned ecosystems, much like early internet protocols that outlasted proprietary silos.
Performance Benchmarks: Real-World zkPoT Viability
Benchmarks reveal ZKBoost's edge in ZKBoost XGBoost integration. On the Higgs dataset, a staple for physics simulations, it proves full training in under 10 minutes on consumer GPUs, retaining 99% accuracy against native XGBoost. Covertype forests, with their million-sample sprawl, clock similar feats via histogram pruning and VOLE-optimized nonlinearities. Compare this to zkGPT's neural net focus or zkVC's matrix-heavy circuits: ZKBoost carves a niche for tree-based models, sidestepping recursion overheads that plague broader zkML.
ZKBoost vs zkML Peers
| Protocol | Proving Time (Higgs dataset) | Accuracy Loss | Max Dataset Size |
|---|---|---|---|
| ZKBoost | 8min | 1% | 1M samples |
| zkVC | 15min | 2% | 500k |
| zkGPT | 20min | 1.5% | 200k |
These metrics aren't lab curiosities; they signal deployability in production pipelines. Fixed-point precision curbs quantization errors, while the generic zkPoT template ports to frameworks like HyperPlonk accelerators. From an investor's vantage, this efficiency builds defensibility - lower costs attract more adopters, thickening the flywheel.
Applications Across High-Stakes Domains
ZKBoost unlocks AI dataset compliance ZK in realms demanding ironclad trust. Financial institutions wielding XGBoost for credit scoring can prove training on licensed datasets, quelling regulatory scrutiny without data dumps. Healthcare diagnostics benefit too: verify models trained on anonymized patient cohorts, enabling federated learning sans central honeypots. In decentralized finance, zkPoTs certify risk engines against adversarial tampering, bolstering protocol resilience.
ZKBoost Applications
- 1. Regulatory compliance audits for finance/healthcare: Verify XGBoost training on sensitive data without disclosure, ensuring audit trails via zkPoT.

- 2. Open-source model sharing with IP protection: Prove correct training provenance while hiding proprietary datasets and parameters.

- 3. DeFi risk modeling verification: Validate risk models on committed data for transparent, tamper-proof DeFi protocols.
- 4. Collaborative training in multi-party datasets: Enable joint XGBoost training across entities without data leakage.

- 5. Bias audits via committed data proofs: Audit model fairness on hidden datasets using verifiable zkPoT.

Researchers, meanwhile, leverage it for reproducible science. Commit your dataset hash, train publicly verifiable models, and collaborate globally - all while shielding proprietary splits. This democratizes access, echoing how open standards propelled cloud adoption.
Challenges persist, sure. Proving latency scales with tree depth, nudging users toward shallower ensembles. Yet, as VOLE hybrids evolve and zkSpeed-like tools proliferate, these evolve into features, not flaws. The Consortium's funding pipeline targets exactly this: modular kernels for sub-minute proofs on terabyte-scale data.
ZKBoost stands at the inflection of cryptography and machine learning, proving that zero knowledge verifiable training isn't a distant promise but a practical lever for trustworthy AI. Its fixed-point ingenuity, VOLE prowess, and ecosystem backing position it for enduring impact, rewarding patient builders with outsized returns in the verifiable computation arena.




No comments yet. Be the first to share your thoughts!