
ZK Proofs for Verifying High-Risk Slices in AI Training Data Provenance

In the rush to build ever-larger AI models, developers often overlook the shadowy corners of their training data: those high-risk slices packed with sensitive personal info, copyrighted materials, or biased content that could trigger regulatory nightmares or lawsuits. Enter zero-knowledge proofs (ZK proofs) for AI training data provenance, a game-changer that lets you verify these risky segments without spilling the beans on the rest of the dataset. This selective approach to model provenance verification isn’t just theoretical; it’s scaling up in real frameworks, slashing compute costs while locking in compliance.


High-risk data slices demand scrutiny because they carry outsized liability. Think medical records in healthcare models or financial docs in trading bots; one leak or misuse, and you’re facing GDPR fines or class-action suits. Traditional audits force full dataset exposure, which kills privacy and stalls innovation. ZK proofs flip the script: prove a model was trained on certified, compliant slices using high-risk data slices ZK techniques, all without revealing the data itself. Provers generate succinct attestations that verifiers check in milliseconds, perfect for enterprise deployments where trust is non-negotiable.
Unpacking the Privacy Paradox in AI Dataset Compliance
AI dataset compliance proofs have evolved from clunky hashes to cryptographic heavyweights. Early attempts relied on Merkle trees for provenance, but they crumbled under scale for massive LLMs. ZK proofs shine here by enabling selective ZK model verification: focus proofs on high-risk subsets, like user-consented data or licensed media, ignoring benign bulk. This sublinear scaling means you don’t re-prove the entire 1TB dataset for one dodgy image batch.
Recent benchmarks back this up. Proving training on an 8B-parameter model clocks under 3.3 seconds end-to-end, per arXiv papers. That’s practical for CI/CD pipelines, not sci-fi. Yet skeptics argue ZK overheads kill speed; reality shows hardware acceleration and protocol tweaks make it viable, especially versus breach cleanup costs.
Key ZK Advancements for AI Data
-

ZKPROV: Framework to verify LLMs trained on certified datasets with sublinear scaling and <3.3s overhead for 8B models. (Namazi et al., arXiv June 2025)
-

zkVerify: Platform enabling millisecond verification for AI training, inference, and provenance with privacy. (zkVerify.io, Feb 2026)
-
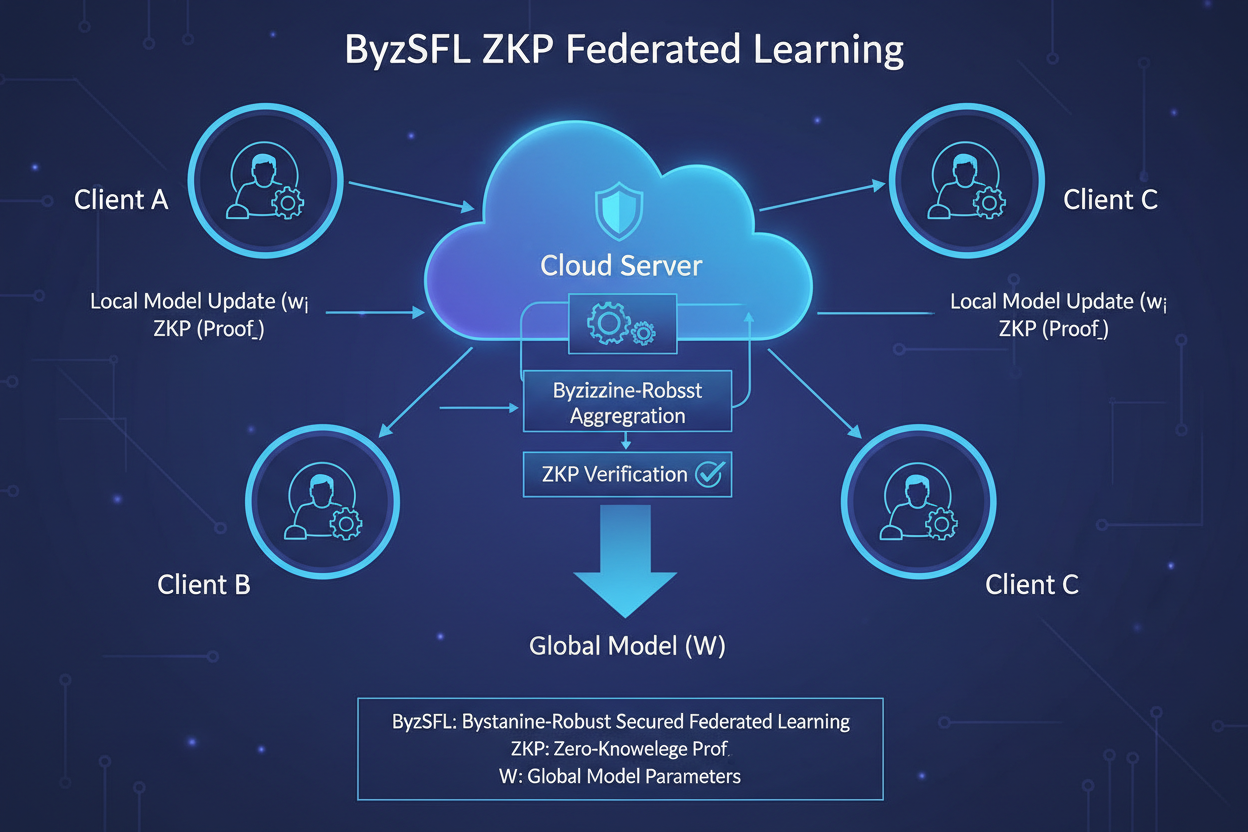
ByzSFL: Byzantine-robust federated learning using ZKPs for 100x speedup in secure aggregation. (Fan et al., arXiv Jan 2025)
-
Verifiable Fine-Tuning: Protocol with succinct ZK proofs confirming fine-tuning from auditable datasets. (Akgul et al., arXiv Oct 2025)
ZKPROV: Pinpointing Dataset Relevance Without Full Disclosure
ZKPROV, from Namazi et al. , nails ZK proofs AI training data for LLMs. Users query a model, and it spits a proof tying responses to authority-certified datasets. No peeking at prompts, weights, or full data; just confirmation that high-risk slices align with query needs. Experiments on models up to 8B params show proofs verifying in seconds, with verifier times dwarfed by API calls.
This framework targets the provenance black hole: was that toxic output from unvetted web scrapes? ZKPROV says prove it wasn’t, selectively. It’s opinionated tech; forces data curators to tag risks upfront, baking accountability into pipelines. Pair it with auditable commitments, and you’ve got ironclad AI dataset compliance proofs.
ByzSFL and Beyond: Robust Aggregation for Risky Federated Data
Federated learning amps the stakes with distributed high-risk slices from hospitals or banks. ByzSFL by Fan et al. deploys ZKPs for Byzantine-robust aggregation, offloading weights to parties while proving correct math privately. It’s 100x faster than rivals, toolkit-ready for plug-and-play. Imagine verifying a model’s healthcare slice drew from compliant federated sources, no central honeypot.
Meanwhile, zkVerify platforms hardware-accelerate proofs for training, inference, even LoRA tweaks. Millisecond checks on provenance ensure fairness quotas hold, zero violations in tests. These tools democratize ZK, letting mid-tier teams compete on trustworthy AI. But here’s the rub: adoption hinges on tooling; raw ZK-SNARKs are byte-small but dev-heavy. Platforms bridge that, prioritizing high-risk slices first.
Verifiable Fine-Tuning protocols take this further, proving a model evolved from a public base through declared programs on committed datasets. Akgul et al. deliver succinct ZK proofs that enforce policy quotas flawlessly, keeping utility high under strict budgets. No more blind trust in fine-tuned trading models handling confidential market data; verify the high-risk slices ZK way, confirming they stayed within licensed bounds.
High-Risk Slices Under the ZK Microscope: Practical Wins
Picture deploying an AI for credit scoring: regulators demand proof that sensitive demographic slices weren’t overrepresented or sourced illegally. Selective ZK model verification zooms in on those subsets, generating proofs that the training respected fairness thresholds and consent logs. Overhead? Negligible post-acceleration. zkVerify’s millisecond validations mean real-time compliance checks during inference, a boon for fintech where seconds count.
I’ve seen teams wrestle with this firsthand; raw datasets balloon to petabytes, but ZK proofs shrink the battle to kilobytes of attestation. It’s not flawless; circuit design demands expertise, and recursive proofs for chained trainings add layers. Still, tools like ZKPROV’s sublinear tricks and ByzSFL’s aggregation kits make it deployable today. Enterprises win by auditing suppliers via proofs, sidestepping data-sharing quagmires.
Comparison of ZK Frameworks for AI Provenance
| Framework | Key Features | Performance Highlights | Source |
|---|---|---|---|
| ZKPROV | Sublinear scaling for proof generation and verification of dataset provenance in LLMs | End-to-end overhead under 3.3s for 8B models | arXiv, June 2025 |
| ByzSFL | Byzantine-robust secure aggregation using ZKPs in federated learning | 100x faster than existing solutions | arXiv, January 2025 |
| Verifiable Fine-Tuning | Succinct ZK proofs for fine-tuning from public initialization and auditable datasets | Zero policy violations | arXiv, October 2025 |
| zkVerify | ZKPs for private model training, inference, provenance, and fairness | Hardware-accelerated proof validation in milliseconds | zkVerify.io, February 2026 |
These aren’t lab curiosities. ChainScore Labs’ ZK receipts trace lineages back to verifiable inputs, ideal for content models dodging copyright claims. Kudelski’s ZKML verifies models against specific content without exposure, targeting high-risk media slices. Even blockchain scaling lessons from a16z apply: off-chain ZK compute for on-chain trust in decentralized AI.
Overcoming Hurdles: From Theory to Trading Desks
Swing trading forex momentum? I blend hybrid signals with news catalysts, but imagine an AI spotting setups trained on licensed feeds only. ZK proofs AI training data ensures no shadow data poisons predictions. Challenges persist: proof sizes stay tiny via SNARKs, yet prover runtimes scale with slice complexity. Experiments on 4GB logistic regressions clock feasible times; extrapolate to LLMs with sharding, and it’s enterprise-ready.
Proteus frameworks prove transformations from originals, crucial for remixed datasets. ZK11 demos link modified content to verified sources, closing provenance loops. My take: prioritize high-risk first. Tag PII, copyrights, biases upfront; prove compliance selectively. This model provenance verification builds moats around AI products, especially as regs like EU AI Act mandate audits.
ZK Steps for High-Risk Data Slices
-
1. Tag & commit risky subsets: Identify high-risk data slices (e.g., sensitive PII) and create cryptographic commitments to datasets without revealing contents, as in ZKPROV framework.
-

2. Train with auditable programs: Use verifiable training programs on committed datasets, ensuring models follow declared processes like in Verifiable Fine-Tuning Protocol.
-
4. Verify in CI/CD: Integrate proof verification into CI/CD pipelines with zkVerify’s hardware-accelerated checks (milliseconds), ensuring compliance pre-deployment.
-

5. Embed attestations: Include ZK proof attestations in model cards for provenance, enabling traceability as in ChainScore Labs’ AI attribution.

Federated setups shine brightest here. Banks sharing fraud patterns without exposing accounts? ByzSFL’s toolkit handles Byzantine faults, proving aggregations privately. Pair with zkVerify for end-to-end: train privately, infer securely, prove provenance. Costs plummet with hardware; a few hundred bucks monthly scales proofs for production.
Forward thinkers at ZKModelProofs. com push this envelope, offering platforms for secure attestations on dataset licensing. Generate proofs proving origins sans secrets, perfect for compliant ML. As AI eats the world, high-risk slices ZK verification isn’t optional; it’s the edge between thriving and litigating. Teams nailing this today capture the swing in trustworthy intelligence, managing the sting of scrutiny head-on.




