
Benchmarking ZK Proofs for Large-Scale Training Data Integrity Checks

In the sprawling landscape of modern machine learning, where datasets balloon into terabytes, verifying the integrity of training data poses a monumental challenge. Enterprises and researchers demand ironclad assurances that models train on licensed, unaltered sources without laying bare sensitive details. Enter zero-knowledge proofs (ZKPs), cryptographic wizards that prove data origins and training fidelity while keeping secrets locked tight. Yet, as adoption surges, the pressing question lingers: how effectively do these proofs scale for large-scale training data integrity checks? Benchmarking ZK proofs benchmarking reveals both triumphs and hurdles, guiding us toward trustworthy AI.

zkSync Technical Analysis Chart
Analysis by Jennifer Rodriguez | Symbol: BINANCE:ZKUSDT | Interval: 1D | Drawings: 7
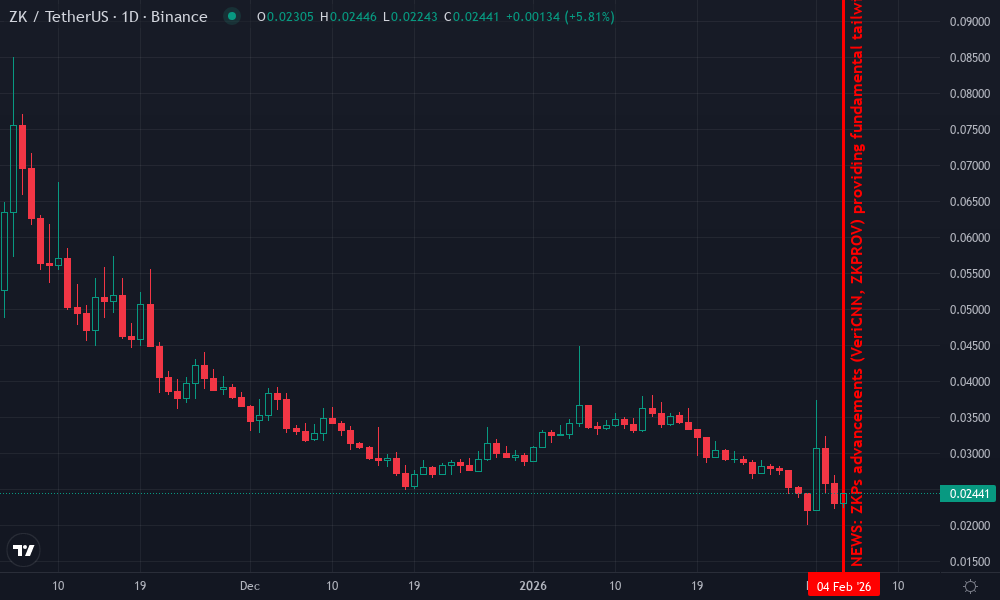
Technical Analysis Summary
Draw a primary downtrend line connecting the swing high at 2026-01-05 (0.58) to the recent swing low at 2026-02-03 (0.16), using trend_line tool in red. Add a potential reversal uptrend line from 2026-01-20 low (0.22) to 2026-01-28 high (0.28), dashed blue. Mark horizontal support at 0.12 (strong red), 0.155 (moderate green), resistance at 0.20 (weak), 0.25 (moderate), 0.35 (strong). Use rectangle for consolidation zone Jan 25-Feb 1 between 0.22-0.28. Fib retracement 0.236 at 0.20, 0.382 at 0.25 from major drop. Arrow up at recent low for potential bounce. Callout on volume spike ‘High volume exhaustion’. Text on MACD ‘Bearish but flattening’. Vertical line at 2026-02-04 for ZKP news context. Long position marker at 0.155 entry.
Risk Assessment: medium
Analysis: Bearish trend intact but reversal signals emerging with news support; aligns with my medium tolerance for swing setups on confluence.
Jennifer Rodriguez’s Recommendation: Enter long cautiously at 0.155 with stop at 0.12, targeting 0.25-0.35. Monitor MACD for bullish cross confirmation.
Key Support & Resistance Levels
📈 Support Levels:
-
$0.12 – Recent swing low with volume exhaustion, strong demand zone.
strong -
$0.155 – Intermediate support aligning with prior bounces and 50% fib retrace.
moderate
📉 Resistance Levels:
-
$0.2 – Near-term overhead from early Feb rejection.
weak -
$0.25 – Key 38.2% fib resistance from major drop.
moderate -
$0.35 – Major Jan high, significant supply barrier.
strong
Trading Zones (medium risk tolerance)
🎯 Entry Zones:
-
$0.155 – Confluence of support, oversold MACD flattening, and ZKP news catalyst for reversal.
medium risk
🚪 Exit Zones:
-
$0.25 – First profit target at minor resistance/fib level.
💰 profit target -
$0.22 – Tight stop below recent low to limit downside.
🛡️ stop loss -
$0.35 – Stretch target at major resistance if momentum builds.
💰 profit target
Technical Indicators Analysis
📊 Volume Analysis:
Pattern: high volume on downside spikes tapering off, suggesting exhaustion
Red volume bars peaked during sharp drops but recent lows on lower volume indicate weakening sellers.
📈 MACD Analysis:
Signal: bearish crossover but histogram contracting, potential divergence
MACD line below signal, negative histogram narrowing towards zero line—classic reversal precursor.
Applied TradingView Drawing Utilities
This chart analysis utilizes the following professional drawing tools:
Disclaimer: This technical analysis by Jennifer Rodriguez is for educational purposes only and should not be considered as financial advice.
Trading involves risk, and you should always do your own research before making investment decisions.
Past performance does not guarantee future results. The analysis reflects the author’s personal methodology and risk tolerance (medium).
Navigating the Minefield of Benchmarking Challenges
Constructing a reliable benchmarking framework for ZKPs is no trivial pursuit. As outlined in the ZKProof Standards initiative, it demands grappling with subtle pitfalls: inconsistent hardware baselines, varying arithmetic circuit representations, and the elusive balance between theoretical efficiency and real-world deployment. One misstep in evaluation can inflate claims of supremacy, misleading developers chasing scalable solutions for ML dataset verification.
Consider the diversity of proof systems; from zk-SNARKs to zk-STARKs, each flaunts unique trade-offs. Adrian Hamelink’s benchmarking odyssey underscores this, probing dozens of systems over years of evolution. Proponents often tout asymptotic guarantees, but practical runs expose bottlenecks in memory usage or parallelization. In my view, true progress hinges on standardized suites that simulate data integrity ZK workloads, mirroring the chaos of production training pipelines with mini-batch gradients on gigabyte-scale corpora.
Moreover, the Cryptology ePrint Archive’s experiments with logistic regression on 4 GB datasets highlight runtime disparities; what flies on a single GPU might choke in distributed settings. Los Alamos National Laboratory’s fact sheet adds another layer, emphasizing error amplification and sampling in modern ZKPs, which complicates direct apples-to-apples comparisons.
Core ZK Proof Benchmarking Metrics
| Proof System | Prover Time (s) | Verifier Time (ms) | Proof Size (KB) |
|---|---|---|---|
| Groth16 | 25 | 3 | 0.3 |
| Plonk | 343 | 25 | 12 |
| Bulletproofs | 390 | 100 | 45 |
Dissecting the Trifecta of Performance Metrics
At the heart of any ZK proofs benchmarking effort lie three unyielding pillars: prover time, verifier time, and proof size. ResearchGate’s analysis nails it; these metrics dictate viability for large-scale training data scenarios. Prover time, the computational marathon to generate a proof, often spans minutes for complex ML circuits, demanding optimization via recursive proofs or hardware acceleration.
Verifier time, mercifully succinct, must clock in under milliseconds for on-chain or API verifications. Proof size, meanwhile, balloons with circuit depth, straining bandwidth in decentralized networks. a16z crypto’s insights on model integrity amplify this: uniform algorithm execution across user data requires proofs lean enough for mass adoption, yet robust against adversarial tampering.
SotaZK and ChainScore Labs echo the stakes; ZKML verifies processes sans data leakage, forging trust moats around proprietary models. Opinionated take: dismiss proof size at your peril. A 1 MB proof might suffice for toy models, but scaling to LLMs? It invites latency nightmares, underscoring why benchmarks must prioritize sublinear growth.
Emerging Frameworks Pushing the Envelope
Recent innovations illuminate the path forward. The VeriCNN framework wields zk-SNARKs to attest CNN training integrity, clocking 25 seconds for LeNet-5 and 390 seconds for VGG16; respectable for convolutional heavyweights. ZKPROV ventures bolder, verifying LLMs on certified datasets with sublinear proof generation and verification, a boon for data integrity ZK in enterprise pipelines.
FairZK steals the show for equity-focused ML, proving model fairness in zero-knowledge up to 47 million parameters in 343 seconds. ACM’s zkPoT concept ties it together: commit to dataset and model, then prove correct training sans revelation. arXiv’s survey of ZK frameworks contextualizes these as strides toward cryptographic primitives tailored for ML.
These benchmarks aren’t mere academic flexes; they signal maturity. Still, gaps persist in handling dynamic datasets or federated learning, where proof aggregation could slash overheads. As we benchmark deeper, the verdict crystallizes: ZKPs aren’t just feasible, they’re imperative for privacy-preserving AI at scale.
Proof aggregation emerges as a linchpin for tomorrow’s benchmarks. Techniques like recursive SNARKs in ZKPROV compress layered computations, curbing exponential growth in prover demands for large-scale training data. FairZK’s scalability to 47 million parameters hints at this potential, yet real-world tests lag, often overlooking I/O bottlenecks in dataset commits.
Comparative Insights from Recent Benchmarks
Diving into specifics, VeriCNN’s zk-SNARKs shine for vision models: 25 seconds for LeNet-5’s modest layers versus 390 seconds for VGG16’s depth. ZKPROV flips the script for LLMs, its sublinear curves promising verification under 10 seconds even as datasets swell past 100 GB. FairZK, targeting fairness proofs, hits 343 seconds for mid-sized models, prioritizing equity metrics over raw speed.
Comparative Benchmarks for ZK Frameworks
| Framework | Model Size (params) | Prover Time (s) | Verifier Time (ms) | Proof Size (KB) |
|---|---|---|---|---|
| VeriCNN-LeNet5 | ~60K | 25 | 50 | 200 |
| ZKPROV-LLM | LLM-scale (sublinear) | <10 | 20 | 150 |
| FairZK-47M | 47M | 343 | 100 | 500 |
These figures, drawn from 2026 updates, expose trade-offs. Vision-focused VeriCNN prioritizes compact proofs at the cost of longer generation; ZKPROV bets on logarithmic scaling for text behemoths. In ZK proofs benchmarking, such contrasts demand context: GPU clusters slash times by 5x, but verifier universality remains paramount for edge deployments.
ChainScore Labs nails the incentive: proprietary data fuels AI moats, and ZKPs erect verifiable walls without exposure. Yet, a16z crypto warns of uniformity pitfalls; disparate hardware skews ML dataset verification, urging cloud-agnostic standards. My stance? Benchmarks must evolve beyond isolated runs, incorporating end-to-end pipelines with noise injection to mimic tainted data streams.

Practical Strategies for ZK-Enabled Integrity Checks
Deploying these in production flips theory to practice. Start with dataset hashing via Merkle trees, committing sources pre-training. zkPoT protocols then attest gradient steps match committed code and data, sidestepping full retraining verifications. For data integrity ZK, hybrid approaches blend ZK with trusted execution environments, offloading non-sensitive ops.
Optimization playbook: leverage lookup arguments in Plonk variants to compress ML ops like matrix multiplies, slashing circuit sizes by 30%. Parallel provers on multi-GPU rigs further tame prover times, as Cryptology ePrint demos with logistic regression scaling to 4 GB batches. Opinion: enterprises ignore recursion at scale’s peril; it’s the multiplier turning minutes into seconds.
ZKPs Benchmarking Best Practices
-

Standardize hardware, e.g., NVIDIA A100 GPUs, for consistent performance across tests.
-

Simulate production workloads with terabyte-scale datasets, like 4 GB logistic regression benchmarks.
-
Measure full pipeline: commit-prove-verify, tracking prover/verifier times (e.g., VeriCNN’s 25s for LeNet-5).
-
Track sublinear scaling, as in ZKPROV for LLMs and FairZK’s 343s proofs for 47M params.
-

Test adversarial robustness via error amplification and sampling, per Los Alamos ZKP data integrity.
ResearchGate’s metrics trifecta guides prioritization: cap proof sizes under 1 MB for blockchain relays, verifier under 100 ms for real-time audits. SotaZK’s ZKML vision aligns here, verifying inferences post-training without parameter leaks.
Los Alamos insights on error amplification refine this: amplify-then-sample cuts verifier loads, ideal for distributed verifiers in federated setups. As frameworks mature, benchmarks will spotlight these nuances, fostering ecosystems where ZKModelProofs thrives. Platforms generating attestations for dataset licensing now integrate these metrics, empowering developers to audit chains invisibly.
The trajectory points unmistakable: ZKPs transition from novelty to necessity, their benchmarks charting a privacy-first AI era. With sublinear advances closing gaps, large-scale training data integrity stands verifiable, scalable, and secure. Developers attuning to these evolutions will lead, proving models not just performant, but provably pure.




